Basic Tutorial
Trey V. Wenger (c) July 2026
Here we demonstrate the basic features of a bayes_spec model.
[1]:
# General imports
import numpy as np
import matplotlib.pyplot as plt
import arviz as az
import pandas as pd
print("arviz version:", az.__version__)
import pymc
print("pymc version:", pymc.__version__)
import bayes_spec
print("bayes_spec version:", bayes_spec.__version__)
# Notebook configuration
pd.options.display.max_rows = None
arviz version: 0.22.0dev
pymc version: 5.22.0
bayes_spec version: 1.9.0+0.g2dc53e3.dirty
Model Definition
First, we define our model. Here we demonstrate a simple Gaussian line profile model where each “cloud” is a set of Gaussian parameters that produces one Gaussian emission line. See the definition of this model in bayes_spec.models.GaussModel, and check out the documentation for guidance on how to create bayes_spec models.
[2]:
from bayes_spec.models import GaussModel
Data Format
We wish to generate some synthetic data from our model, which requires us to take a brief aside to introduce the bayes_spec data format. We use the SpecData class to pass data into bayes_spec.
[3]:
from bayes_spec import SpecData
# spectral axis definition
velocity_axis = np.linspace(-250.0, 250.0, 501) # km/s
# data noise can either be a scalar (assumed constant noise across the spectrum)
# or an array of the same length as the data
noise = 1.0 # K
# brightness data. In this case, we just throw in some random data for now
# since we are only doing this in order to simulate some actual data.
brightness_data = noise * np.random.randn(len(velocity_axis)) # K
# Our model only expects a single observation named "observation"
# Note that because we "named" the spectrum "observation" here,
# we must use the same name in the model definition above
observation = SpecData(
velocity_axis,
brightness_data,
noise,
xlabel=r"Velocity (km s$^{-1}$)",
ylabel="Brightness Temperature (K)",
)
dummy_data = {"observation": observation}
Simulating Data
Now that we have a model definition and a dummy data format, we can generate simulated observations by drawing samples from the parameter prior distributions.
[4]:
# Initialize and define the model
n_clouds = 3
baseline_degree = 2
model = GaussModel(dummy_data, n_clouds=n_clouds, baseline_degree=baseline_degree, ripples=True, seed=1234, verbose=True)
model.add_priors(
prior_line_area = 500.0, # mode of k=2 gamma distribution prior on line area (K km s-1)
prior_fwhm = 25.0, # mode of k=2 gamma distribution prior on FWHM line width (km s-1)
prior_velocity = [0.0, 50.0], # mean and width of normal distribution prior on centroid velocity (km s-1)
prior_baseline_coeffs = [1.0, 1.0, 1.0], # width of normal distribution prior on normalized baseline coefficients
prior_ripple_amplitude = 1.0, # width of half-normal distribution prior on normalized ripple amplitude
prior_ripple_wavenumber = [10.0, 1.0], # mean and width of normal distribution prior on normalized ripple wavenumber
prior_ripple_phase = [0.0, 0.01], # mean and concentration on Von Mises prior distribution on ripple phase
)
model.add_likelihood()
# Draw one posterior predictive sample
simulated = model.sample_prior_predictive(
samples=1,
)
sim_brightness = simulated.prior_predictive["observation"].sel(chain=0, draw=0).data
# Plot the simulated data
plt.plot(dummy_data["observation"].spectral, sim_brightness, 'k-')
plt.xlabel(dummy_data["observation"].xlabel)
_ = plt.ylabel(dummy_data["observation"].ylabel)
Sampling: [baseline_observation_norm, fwhm_norm, line_area_norm, observation, ripple_observation_amplitude_norm, ripple_observation_phase_norm, ripple_observation_wavenumber_norm, velocity_norm]
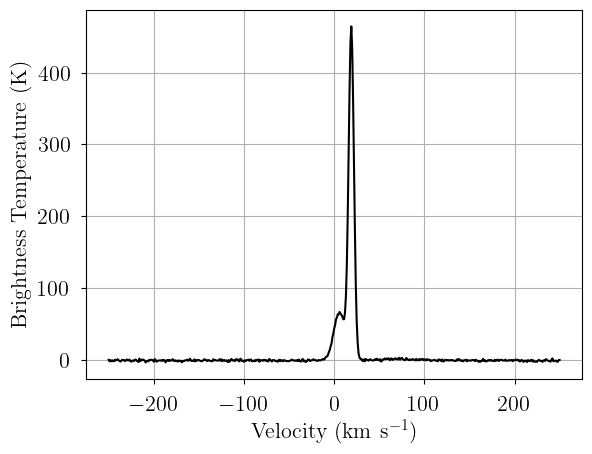
Alternatively, we can pass the relevant parameters directly to the likelihood variable, named observation in our model, to evaluate a model with specific model parameters. Be sure that the simulated values are reasonable given your prior distributions!
[5]:
sim_params = {
"fwhm": [25.0, 40.0, 35.0], # FWHM line width (km/s)
"line_area": [250.0, 125.0, 175.0], # line area (K km/s)
"velocity": [-35.0, 10.0, 55.0], # velocity (km/s)
"baseline_observation_norm": [-0.5, -2.0, 3.0], # normalized baseline coefficients
"ripple_observation_amplitude_norm": 1.0, # normalized ripple amplitude
"ripple_observation_wavenumber_norm": 10.0, # normalized ripple wavelength
"ripple_observation_phase_norm": 0.2, # ripple phase
}
# add derived quantities to sim_params
for key in model.cloud_deterministics:
if key not in sim_params.keys():
sim_params[key] = model.model[key].eval(sim_params, on_unused_input="ignore")
# Evaluate and save simulated observation
sim_brightness = model.model.observation.eval(sim_params, on_unused_input="ignore")
# Plot the simulated data
plt.plot(dummy_data["observation"].spectral, sim_brightness, 'k-')
plt.xlabel(dummy_data["observation"].xlabel)
_ = plt.ylabel(dummy_data["observation"].ylabel)
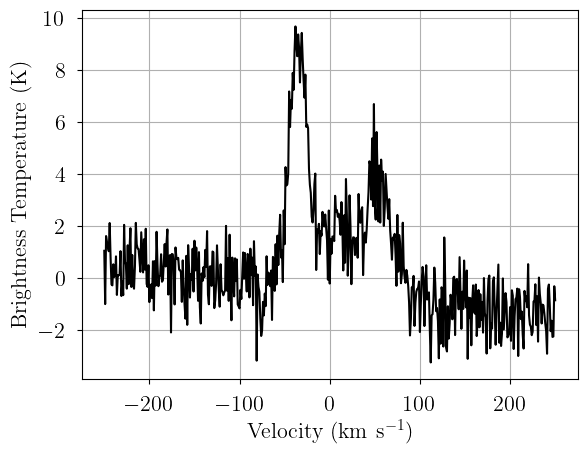
[6]:
sim_params
[6]:
{'fwhm': [25.0, 40.0, 35.0],
'line_area': [250.0, 125.0, 175.0],
'velocity': [-35.0, 10.0, 55.0],
'baseline_observation_norm': [-0.5, -2.0, 3.0],
'ripple_observation_amplitude_norm': 1.0,
'ripple_observation_wavenumber_norm': 10.0,
'ripple_observation_phase_norm': 0.2,
'amplitude': array([9.39437279, 2.9357415 , 4.69718639])}
[7]:
# Now we pack the simulated spectrum into a new SpecData instance
observation = SpecData(
velocity_axis,
sim_brightness,
noise,
xlabel=r"Velocity (km s$^{-1}$)",
ylabel="Brightness Temperature (K)",
)
data = {"observation": observation}
Model
Finally, with our model definition and (simulated) data in hand, we can explore the capabilities of bayes_spec.
We begin with a three-cloud (n_cloud=3) model, with a 2nd order polynomial baseline (baseline_degree=2). Each “cloud” is a set of Gaussian parameters that produces a single Gaussian emission line. The length of prior_baseline_coeffs must be baseline_degree + 1, and generally can be left at the default value since the data and baseline are internally normalized.
[8]:
model = GaussModel(data, n_clouds=n_clouds, baseline_degree=baseline_degree, ripples=True, seed=1234, verbose=True)
model.add_priors(
prior_line_area = 500.0, # mode of k=2 gamma distribution prior on line area (K km s-1)
prior_fwhm = 25.0, # mode of k=2 gamma distribution prior on FWHM line width (km s-1)
prior_velocity = [0.0, 50.0], # mean and width of normal distribution prior on centroid velocity (km s-1)
prior_baseline_coeffs = [1.0, 1.0, 1.0], # width of normal distribution prior on normalized baseline coefficients
prior_ripple_amplitude = 1.0, # width of half-normal distribution prior on normalized ripple amplitude
prior_ripple_wavenumber = [10.0, 1.0], # mean and width of normal distribution prior on normalized ripple wavenumber
prior_ripple_phase = [0.0, 0.01], # mean and concentration on Von Mises prior distribution on ripple phase
)
model.add_likelihood()
[9]:
# Plot model graph
model.graph()
[9]:

The model graph shows the relationship between the free parameters (ellipses), derived quantities (rectangles), and observed data (filled ellipses). Each “group” or “box” describes groups of parameters or values with a specific dimension: since baseline_degree=2 then baseline_coeff has length 3, since n_clouds=3 the number of clouds is 3, and there are 501 data points (channels) in our spectrum (observation).
[10]:
# model string representation
print(model.model.str_repr())
baseline_observation_norm ~ Normal(0, <constant>)
ripple_observation_amplitude_norm ~ HalfNormal(0, 1)
ripple_observation_wavenumber_norm ~ Normal(10, 1)
ripple_observation_phase_norm ~ VonMises(0, 0.01)
line_area_norm ~ Gamma(2, f())
fwhm_norm ~ Gamma(2, f())
velocity_norm ~ Normal(0, 1)
line_area ~ Deterministic(f(line_area_norm))
fwhm ~ Deterministic(f(fwhm_norm))
velocity ~ Deterministic(f(velocity_norm))
amplitude ~ Deterministic(f(fwhm_norm, line_area_norm))
observation ~ Normal(f(ripple_observation_amplitude_norm, ripple_observation_phase_norm, fwhm_norm, line_area_norm, ripple_observation_wavenumber_norm, baseline_observation_norm, velocity_norm), <constant>)
We check that our prior distributions are reasonable by drawing prior predictive checks. Each colored line is a simulated “observation” with parameters drawn from the prior distributions. You should check that these simulated observations at least somewhat overlap your actual observation (black line).
[11]:
from bayes_spec.plots import plot_predictive
# prior predictive check
prior = model.sample_prior_predictive(
samples=1000, # prior predictive samples
)
_ = plot_predictive(model.data, prior.prior_predictive)
Sampling: [baseline_observation_norm, fwhm_norm, line_area_norm, observation, ripple_observation_amplitude_norm, ripple_observation_phase_norm, ripple_observation_wavenumber_norm, velocity_norm]

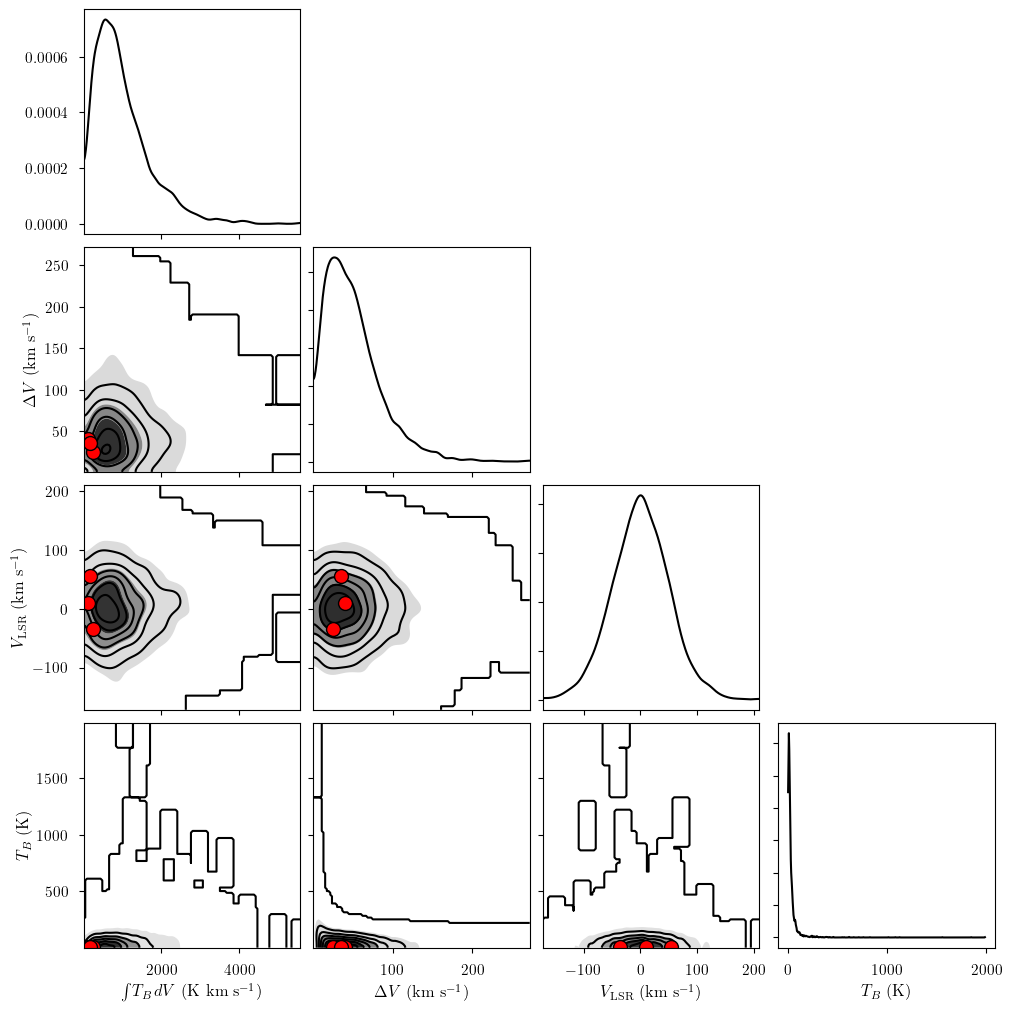
We can also generate a pair plot to inspect the prior distributions and their effect on deterministic quantities. The model has several attributes to access the various free parameters (freeRVs) and deterministic quantities (deterministics). Here we show the pair plot for the deterministic quantities derived from our prior distributions. The three red points correspond to the simulation parameters (“truths”) for our three clouds.
[12]:
from bayes_spec.plots import plot_pair
# available parameter attributes:
print("baseline_freeRVs", model.baseline_freeRVs)
print("baseline_deterministics", model.baseline_deterministics)
print("cloud_freeRVs", model.cloud_freeRVs)
print("cloud_deterministics", model.cloud_deterministics)
print("hyper_freeRVs", model.hyper_freeRVs)
print("hyper_deterministics", model.hyper_deterministics)
_ = plot_pair(
prior.prior, # samples
model.cloud_deterministics, # var_names to plot
combine_dims=["cloud"], # concatenate clouds
labeller=model.labeller, # label manager
kind="kde", # plot type
reference_values=sim_params, # truths
)
baseline_freeRVs ['baseline_observation_norm']
baseline_deterministics []
cloud_freeRVs ['line_area_norm', 'fwhm_norm', 'velocity_norm']
cloud_deterministics ['line_area', 'fwhm', 'velocity', 'amplitude']
hyper_freeRVs ['ripple_observation_amplitude_norm', 'ripple_observation_wavenumber_norm', 'ripple_observation_phase_norm']
hyper_deterministics []
Posterior Sampling: Variational Inference
We can approximate the posterior distribution using variational inference (VI). We will run a maximum of n iterations, but stop early if it appears that VI has converged on a solution. You will have to tune the convergence thresholds and learning rate for your model. We help the sampler along by initializing the velocity parameter over the range of the prior.
[13]:
model.fit(
n = 100_000, # maximum number of VI iterations
draws = 1_000, # number of posterior samples
rel_tolerance = 0.01, # VI relative convergence threshold
abs_tolerance = 0.05, # VI absolute convergence threshold
learning_rate = 1e-2, # VI learning rate
start = {"velocity_norm": np.linspace(-3.0, 3.0, n_clouds)},
)
Convergence achieved at 5400
Interrupted at 5,399 [5%]: Average Loss = 2,079.3
Adding log-likelihood to trace
[14]:
# posterior samples stored in model.trace.posterior
az.summary(model.trace.posterior)
arviz - WARNING - Shape validation failed: input_shape: (1, 1000), minimum_shape: (chains=2, draws=4)
[14]:
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| baseline_observation_norm[0] | -0.395 | 0.045 | -0.474 | -0.304 | 0.001 | 0.001 | 958.0 | 749.0 | NaN |
| baseline_observation_norm[1] | -1.888 | 0.050 | -1.978 | -1.794 | 0.002 | 0.001 | 949.0 | 983.0 | NaN |
| baseline_observation_norm[2] | 2.422 | 0.090 | 2.254 | 2.587 | 0.003 | 0.002 | 970.0 | 983.0 | NaN |
| ripple_observation_wavenumber_norm | 9.970 | 0.033 | 9.903 | 10.028 | 0.001 | 0.001 | 967.0 | 910.0 | NaN |
| velocity_norm[0] | -4.184 | 0.220 | -4.616 | -3.786 | 0.007 | 0.005 | 919.0 | 908.0 | NaN |
| velocity_norm[1] | -0.690 | 0.008 | -0.704 | -0.675 | 0.000 | 0.000 | 1024.0 | 890.0 | NaN |
| velocity_norm[2] | 0.829 | 0.029 | 0.779 | 0.886 | 0.001 | 0.001 | 967.0 | 975.0 | NaN |
| ripple_observation_amplitude_norm | 1.181 | 0.064 | 1.068 | 1.307 | 0.002 | 0.001 | 1022.0 | 813.0 | NaN |
| ripple_observation_phase_norm | 0.283 | 0.052 | 0.195 | 0.386 | 0.002 | 0.001 | 985.0 | 885.0 | NaN |
| line_area_norm[0] | 0.157 | 0.024 | 0.120 | 0.204 | 0.001 | 0.001 | 1053.0 | 1024.0 | NaN |
| line_area_norm[1] | 0.501 | 0.012 | 0.479 | 0.524 | 0.000 | 0.000 | 956.0 | 983.0 | NaN |
| line_area_norm[2] | 0.566 | 0.021 | 0.527 | 0.604 | 0.001 | 0.000 | 948.0 | 750.0 | NaN |
| fwhm_norm[0] | 3.939 | 0.675 | 2.724 | 5.242 | 0.021 | 0.017 | 1002.0 | 1017.0 | NaN |
| fwhm_norm[1] | 1.020 | 0.032 | 0.957 | 1.076 | 0.001 | 0.001 | 972.0 | 944.0 | NaN |
| fwhm_norm[2] | 2.698 | 0.108 | 2.493 | 2.894 | 0.004 | 0.003 | 849.0 | 732.0 | NaN |
| line_area[0] | 78.320 | 11.846 | 59.837 | 102.092 | 0.363 | 0.315 | 1053.0 | 1024.0 | NaN |
| line_area[1] | 250.449 | 6.034 | 239.292 | 261.985 | 0.194 | 0.138 | 956.0 | 983.0 | NaN |
| line_area[2] | 283.215 | 10.439 | 263.499 | 302.141 | 0.340 | 0.240 | 948.0 | 750.0 | NaN |
| fwhm[0] | 98.487 | 16.863 | 68.100 | 131.046 | 0.534 | 0.431 | 1002.0 | 1017.0 | NaN |
| fwhm[1] | 25.496 | 0.800 | 23.929 | 26.905 | 0.026 | 0.019 | 972.0 | 944.0 | NaN |
| fwhm[2] | 67.442 | 2.711 | 62.334 | 72.342 | 0.093 | 0.073 | 849.0 | 732.0 | NaN |
| velocity[0] | -209.183 | 11.025 | -230.791 | -189.298 | 0.365 | 0.250 | 919.0 | 908.0 | NaN |
| velocity[1] | -34.509 | 0.388 | -35.181 | -33.773 | 0.012 | 0.008 | 1024.0 | 890.0 | NaN |
| velocity[2] | 41.440 | 1.445 | 38.931 | 44.322 | 0.047 | 0.033 | 967.0 | 975.0 | NaN |
| amplitude[0] | 0.769 | 0.176 | 0.475 | 1.100 | 0.005 | 0.005 | 1057.0 | 944.0 | NaN |
| amplitude[1] | 9.237 | 0.366 | 8.527 | 9.898 | 0.012 | 0.008 | 966.0 | 944.0 | NaN |
| amplitude[2] | 3.952 | 0.220 | 3.558 | 4.350 | 0.007 | 0.005 | 943.0 | 818.0 | NaN |
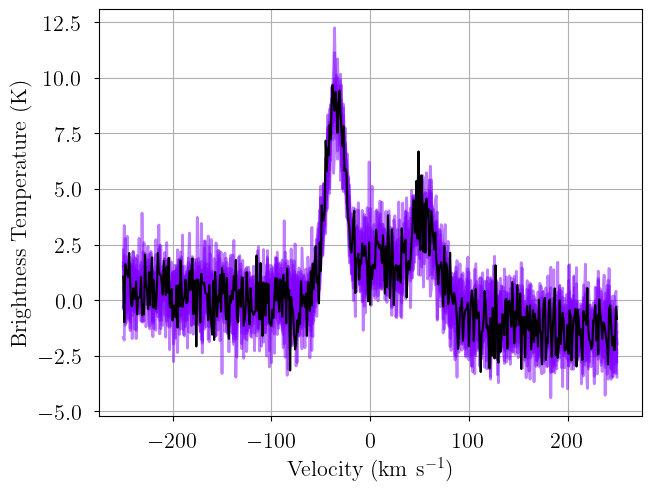
It’s good practice to verify the integrity of your solution! Here we generate posterior predictive checks – realizations of the model drawn with parameters drawn from the posterior distribution. Each line is one posterior sample.
[15]:
posterior = model.sample_posterior_predictive(
thin=100, # keep one in {thin} posterior samples
)
_ = plot_predictive(model.data, posterior.posterior_predictive)
Sampling: [observation]
Posterior Sampling: MCMC
VI is fast, but it’s not particularly accurate, and there is no way to diagnose “convergence”. Instead, we sample the posterior distribution using MCMC. Here we initialize the No U-Turn Sampler (NUTS) using VI (also available is the pymc default: init="jitter+adapt_diag", which may be better suited to some models). We can customize the VI initialization as well as the NUTS parameters. If there are many divergences, or if the resulting effective sample sizes are small and r_hat is
large, try increasing the number of tuning samples, draws, and/or chains. Increasing target_accept to 0.9 or 0.95 can help if there are many divergences. Use as many chains as possible.
[16]:
init_kwargs = {
"rel_tolerance": 0.01,
"abs_tolerance": 0.01,
"learning_rate": 0.001,
"start": {"velocity_norm": np.linspace(-3.0, 3.0, model.n_clouds)},
}
model.sample(
init = "advi+adapt_diag", # initialization strategy
tune = 1000, # tuning samples
draws = 1000, # posterior samples
chains = 8, # number of independent chains
cores = 8, # number of parallel chains
init_kwargs = init_kwargs, # VI initialization arguments
nuts_kwargs = {"target_accept": 0.8}, # NUTS arguments
)
Initializing NUTS using custom advi+adapt_diag strategy
Convergence achieved at 30600
Interrupted at 30,599 [3%]: Average Loss = 3,033
Multiprocess sampling (8 chains in 8 jobs)
NUTS: [baseline_observation_norm, ripple_observation_amplitude_norm, ripple_observation_wavenumber_norm, ripple_observation_phase_norm, line_area_norm, fwhm_norm, velocity_norm]
Sampling 8 chains for 1_000 tune and 1_000 draw iterations (8_000 + 8_000 draws total) took 5 seconds.
Adding log-likelihood to trace
If a chain does not converge, an error is printed and that chain is dropped from all subsequent analyses. In the remaining chains, there may be some divergences. The number of divergences should be much less than the number of posterior samples.
In general, there could be a labeling degeneracy, or multiple unique solutions. Here we “solve” for those effects using a Gaussian Mixture Model (GMM). The parameter kl_div_threshold defines the probability threshold for “unique” GMM solutions.
[17]:
model.solve(kl_div_threshold=0.1)
GMM converged to unique solution
7 of 8 chains appear converged.
Label order mismatch in solution 0
Chain 0 order: [1 2 0]
Chain 1 order: [0 2 1]
Chain 2 order: [1 2 0]
Chain 3 order: [1 2 0]
Chain 5 order: [1 2 0]
Chain 6 order: [1 2 0]
Chain 7 order: [1 2 0]
Adopting (first) most common order: [1 2 0]
[18]:
print("solutions:", model.solutions)
display(az.summary(model.trace["solution_0"]))
# this also works: az.summary(model.trace.solution_0)
solutions: [0]
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| baseline_observation_norm[0] | -0.451 | 0.121 | -0.674 | -0.218 | 0.002 | 0.002 | 3667.0 | 3822.0 | 1.0 |
| baseline_observation_norm[1] | -2.091 | 0.051 | -2.189 | -1.999 | 0.001 | 0.001 | 8486.0 | 5193.0 | 1.0 |
| baseline_observation_norm[2] | 2.882 | 0.197 | 2.510 | 3.245 | 0.003 | 0.002 | 4069.0 | 4363.0 | 1.0 |
| ripple_observation_wavenumber_norm | 9.970 | 0.035 | 9.905 | 10.038 | 0.000 | 0.000 | 7986.0 | 4740.0 | 1.0 |
| velocity_norm[0] | 0.285 | 0.126 | 0.054 | 0.523 | 0.003 | 0.002 | 2519.0 | 3377.0 | 1.0 |
| velocity_norm[1] | -0.709 | 0.009 | -0.725 | -0.692 | 0.000 | 0.000 | 5804.0 | 4822.0 | 1.0 |
| velocity_norm[2] | 1.139 | 0.029 | 1.084 | 1.194 | 0.000 | 0.000 | 3727.0 | 4066.0 | 1.0 |
| ripple_observation_amplitude_norm | 1.005 | 0.073 | 0.868 | 1.145 | 0.001 | 0.001 | 6301.0 | 5347.0 | 1.0 |
| ripple_observation_phase_norm | 0.185 | 0.072 | 0.052 | 0.321 | 0.001 | 0.001 | 6665.0 | 5002.0 | 1.0 |
| line_area_norm[0] | 0.415 | 0.091 | 0.250 | 0.583 | 0.002 | 0.001 | 2209.0 | 3370.0 | 1.0 |
| line_area_norm[1] | 0.426 | 0.033 | 0.362 | 0.485 | 0.001 | 0.000 | 2877.0 | 4021.0 | 1.0 |
| line_area_norm[2] | 0.238 | 0.055 | 0.147 | 0.344 | 0.001 | 0.001 | 2383.0 | 3227.0 | 1.0 |
| fwhm_norm[0] | 2.921 | 0.577 | 1.876 | 3.981 | 0.012 | 0.006 | 2333.0 | 3262.0 | 1.0 |
| fwhm_norm[1] | 0.890 | 0.050 | 0.800 | 0.986 | 0.001 | 0.001 | 3753.0 | 4993.0 | 1.0 |
| fwhm_norm[2] | 1.168 | 0.168 | 0.872 | 1.494 | 0.003 | 0.002 | 2687.0 | 4244.0 | 1.0 |
| line_area[0] | 207.571 | 45.386 | 125.170 | 291.737 | 0.961 | 0.550 | 2209.0 | 3370.0 | 1.0 |
| line_area[1] | 213.071 | 16.709 | 180.790 | 242.370 | 0.312 | 0.166 | 2877.0 | 4021.0 | 1.0 |
| line_area[2] | 119.239 | 27.263 | 73.433 | 172.187 | 0.564 | 0.324 | 2383.0 | 3227.0 | 1.0 |
| fwhm[0] | 73.023 | 14.418 | 46.889 | 99.521 | 0.299 | 0.161 | 2333.0 | 3262.0 | 1.0 |
| fwhm[1] | 22.258 | 1.246 | 19.998 | 24.643 | 0.020 | 0.013 | 3753.0 | 4993.0 | 1.0 |
| fwhm[2] | 29.200 | 4.201 | 21.795 | 37.349 | 0.081 | 0.052 | 2687.0 | 4244.0 | 1.0 |
| velocity[0] | 14.230 | 6.302 | 2.708 | 26.133 | 0.126 | 0.082 | 2519.0 | 3377.0 | 1.0 |
| velocity[1] | -35.438 | 0.433 | -36.249 | -34.618 | 0.006 | 0.005 | 5804.0 | 4822.0 | 1.0 |
| velocity[2] | 56.972 | 1.466 | 54.199 | 59.699 | 0.024 | 0.018 | 3727.0 | 4066.0 | 1.0 |
| amplitude[0] | 2.670 | 0.236 | 2.227 | 3.122 | 0.003 | 0.002 | 4808.0 | 5561.0 | 1.0 |
| amplitude[1] | 8.990 | 0.438 | 8.191 | 9.805 | 0.007 | 0.004 | 4432.0 | 5611.0 | 1.0 |
| amplitude[2] | 3.811 | 0.520 | 2.855 | 4.791 | 0.009 | 0.005 | 3291.0 | 4736.0 | 1.0 |
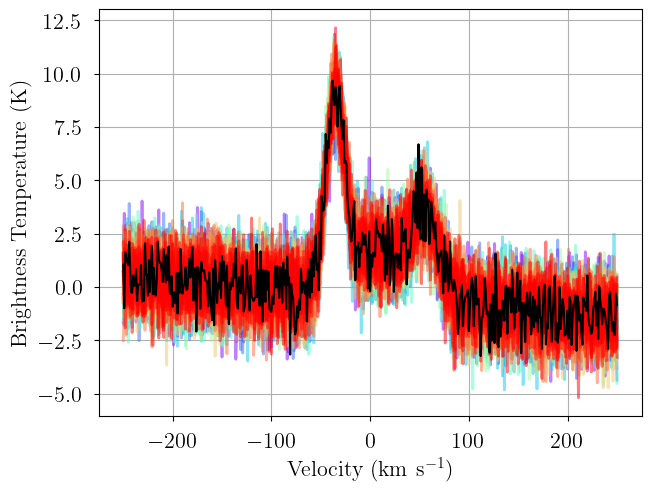
We again generate posterior predictive checks as well as a trace plot of the individual chains. Each line is one posterior sample.
[19]:
posterior = model.sample_posterior_predictive(
thin=100, # keep one in {thin} posterior samples
)
_ = plot_predictive(model.data, posterior.posterior_predictive)
Sampling: [observation]
[20]:
from bayes_spec.plots import plot_traces
axes = plot_traces(model.trace.solution_0, model.cloud_freeRVs + model.baseline_freeRVs + model.hyper_freeRVs)
fig = axes.ravel()[0].figure
fig.tight_layout()

In these trace plots, each linestyle represents a different Markov chain (there are four different chains and linestyles), and each color represents a different parameter group. For example, there are three colors for line_area_norm representing the three clouds of the model, and there are three colors for baseline_observation_norm representing the three baseline coefficients (since baseline_degree=2 there are three polynomial baseline coefficients).
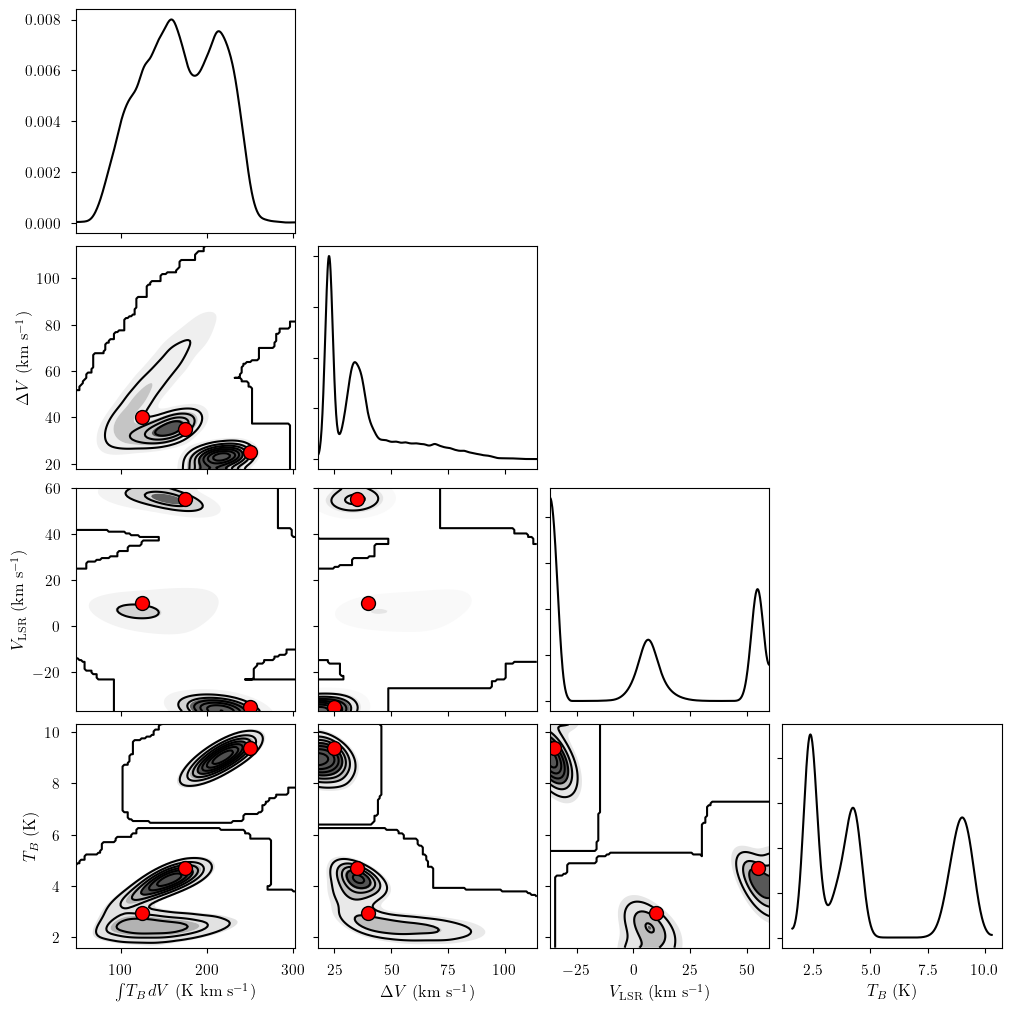
We can inspect the posterior distribution pair plots. First, the free cloud parameters.
[21]:
_ = plot_pair(
model.trace.solution_0, # samples
model.cloud_freeRVs, # var_names to plot
combine_dims=["cloud"], # concatenate clouds
labeller=model.labeller, # label manager
kind="kde", # plot type
reference_values=sim_params, # truths
)

Notice that there are three posterior modes. These correspond to the three clouds of the model. We can plot each cloud against the other to see degeneracies between clouds.
[22]:
_ = plot_pair(
model.trace.solution_0, # samples
model.cloud_freeRVs, # var_names to plot
combine_dims=None, # do not concatenate clouds
labeller=model.labeller, # label manager
kind="kde", # plot type
reference_values=sim_params, # truths
)

And the cloud deterministic quantities.
[23]:
_ = plot_pair(
model.trace.solution_0, # samples
model.cloud_deterministics, # var_names to plot
combine_dims=["cloud"], # concatenate clouds
labeller=model.labeller, # label manager
kind="kde", # plot type
reference_values=sim_params, # truths
)
We can plot the posterior distributions for a single cloud.
[24]:
my_true_cloud = 1
my_sim_params = {}
for var_name in model.cloud_deterministics:
my_sim_params[var_name] = sim_params[var_name][my_true_cloud]
for var_name in model.baseline_freeRVs:
my_sim_params[var_name] = sim_params[var_name]
for var_name in model.hyper_freeRVs:
my_sim_params[var_name] = sim_params[var_name]
_ = plot_pair(
model.trace.solution_0.sel(cloud=0), # samples
model.cloud_deterministics + model.baseline_freeRVs + model.hyper_freeRVs, # var_names to plot
labeller=model.labeller, # label manager
kind="kde", # plot type
reference_values=my_sim_params, # truths
)

Finally, we can get the posterior statistics, Bayesian Information Criterion (BIC), etc.
[25]:
point_stats = az.summary(model.trace.solution_0, var_names=model.cloud_deterministics, kind='stats', hdi_prob=0.68)
print("BIC:", model.bic())
point_stats
BIC: 1527.1343269286199
[25]:
| mean | sd | hdi_16% | hdi_84% | |
|---|---|---|---|---|
| line_area[0] | 207.571 | 45.386 | 153.414 | 245.350 |
| line_area[1] | 213.071 | 16.709 | 197.148 | 231.277 |
| line_area[2] | 119.239 | 27.263 | 86.771 | 141.928 |
| fwhm[0] | 73.023 | 14.418 | 58.436 | 88.201 |
| fwhm[1] | 22.258 | 1.246 | 21.032 | 23.526 |
| fwhm[2] | 29.200 | 4.201 | 24.998 | 33.206 |
| velocity[0] | 14.230 | 6.302 | 8.266 | 20.639 |
| velocity[1] | -35.438 | 0.433 | -35.890 | -35.036 |
| velocity[2] | 56.972 | 1.466 | 55.650 | 58.479 |
| amplitude[0] | 2.670 | 0.236 | 2.432 | 2.899 |
| amplitude[1] | 8.990 | 0.438 | 8.539 | 9.412 |
| amplitude[2] | 3.811 | 0.520 | 3.221 | 4.281 |
[ ]: